Spokes v1.4.5
Published at February 8, 2024 · 16 min read
Share on:We’re pleased to announce Spokes v1.4.5. This release has been under development for several months and introduces a lot of new functionality. Along its development we discovered room for optimizations and bug fixes that improve performance and memory utilization.
Get the Release!
You can download the RPM here. Our container is available at our packetriot repo and now the Terrapin Labs repo as well.
docker pull packetriot/spokes:1.4.5
# alternatively
docker pull terrapinlabs/spokes:1.4.5
Memory Optimizations
We discovered the need for memory optimizations in Spokes, particularly when allocations in some routines would outpace the garbage collector (GC). This would create a slow but persistent growth in memory usage. For Spokes containers deployed via containers or on hosts with a small amount of memory (1GB) a crash might occur after a few weeks.
There were some instances where periodic monitors and other routines created a similar issue with allocations growing faster than the GC could keep up with.
The discovery of these issues is credited to new monitoring tools we deployed on the Packetriot network to check on the health of the hosts that composed our network and the containers running our software. We noticed containers restarting more frequently then we realized. The restart time is quick, so our uptime monitors never picked this up.
I’m sure we will find more opportunities to make optimizations in the future. Our monitoring tools will allow us to see the how our improvements are working across a fleet of differently utilized servers.
The two sub-sections below describe the issues we found and how we fixed them.
TLS Termination
Spokes supports TLS terminations for certificates managed externally. This feature is not exposed in the admin dashboard but can be customized by creating sub-directories in/var/lib/spokes/certs-extra and storing the relevant certificates and keys in them.
Packetriot can be used as an example here. We use a wildcard certificate for all of *.pktriot.net that are assigned to tunnels on the Packetriot network. A sub-directory called wildcard_.pktriot.net is created and we store the certificate and private key there. Spokes will walk this directory at start-up, and periodically thereafter, and set up a new or updated TLS listener using the server name in the certificate.
We fixed a memory growth issue here by using a pool of buffers for reading the initial HTTP/S requests for domains that match the custom TLS certificates. Memory allocations dropped dramatically and management of the heap by the GC keeps the overall memory footprint much lower now.
Heartbeats
We discovered that the constant heartbeats we use to determine that tunnels are online contributed to the allocations that overtook the GC’s ability to clean up unused memory.
A variety of heartbeat signals trigger internal operations in Spokes that would perform database queries and subsequent updates. Since the time interval of these heartbeats is small, the memory allocations of these operations also made it difficult for the GC to keep up. We analyze many code paths where database fetches/updates were made very often and updated the logic to use cached values or perform updates with more optimized SQL statements.
This issue along with the TLS termination heap growth contributed to crashes that would occur eventually. We’re glad that we finally discovered this issue, it was only discovered once we started instrumenting and monitoring our network in more detail.
High-Availability Replication & Failover
The release introduces our initial approach for providing inter and cross-region high-availability (HA).
We provided a high-availability feature in Spokes for some time now, but it only supported an HA configuration in a single region or datacenter. Two or more instances of Spokes could be hosted behind a load balancer such as an AWS Elastic Load Balancer (ELB).
The Spokes server can be started with the flag --ha-mode along with some additional parameters for failure tolerances. In this mode, Spokes will use the domain value in the configuration and check if its available. If it is, then this instance would continue to perform its health check. Once 1-n failures to connect occurred, then it would fully start up to recover from the failure on previously running primary server.
This configuration allowed a load balancer to send traffic to one primary Spokes instance since the backup was not fully running.
Using a shared filesystem such as AWS Elastic Filesystem (EFS) made it simple to keep both Spokes instance consistent: data, licenses, TLS certificates and configuration. This approach is simple and works great when high-availability across different zones in a datacenter is your requirement. However, when you need cross-region HA, that is a different and much more challenging problem.
In this release, Spokes is providing its initial implementation to provide cross-region HA.
Technical Approach
Cross-region HA requires consistent data across the servers that are scattered across the different regions. We leveraged our existing webhook publishing modules and admin APIs to implement an event-based approach for communicating updates from the master node to the replica nodes.
A periodically synchronization by replica nodes is performed that creates a snapshot for all of the critical information required for each node to be consistent. These snapshots do not include data such as connection metrics, alerts, admin events, etc.
The data that is replicated includes:
- Registration Tokens
- Tunnels and Authentication Tokens
- Port allocations
- Users (basic and admins) and Domain Restrictions
- Replica Information
Even with thousands of tunnels, this is a small amount of data that is in size-range of megabytes. In the future, more data will be added such as TLS certificates. These are the TLS certificates mentioned earlier in this post that are stored in /var/lib/spokes/certs-extra.
The Spokes server required new functionality to communicates all this critical information across the HA cluster. Spokes also needed new configuration options so that master and replica nodes could be identified.
Incoming traffic to replica nodes also need to be backhauled to the master node when it can’t be served locally by the replica.
In the next sections below we’ll describe all the new features in more detail. Discuss how recovery options will are performed in this current version and upcoming versions. And we’ll discuss our roadmap for high-availability in Spokes and our goal to make it the most simple and automated network server that supports cross-region HA.
Server Configuration
Each Spokes server in the high-availability cluster requires additional configuration that will setup each node as a master or replica node.
A cluster always has one master node and 0-n replica nodes. Each node has its own unique hostname. The cluster has a hostname as well that will resolve to any of the nodes. This is implemented using 1-n CNAME records that ALIAS the master and all replica hostnames.
This approach provides network load balancing and robustness.
Client tunnels can establish connections to all the servers in the cluster, or just the master node since replicas will backhaul incoming traffic requests they can’t serve to it.
Below is a screenshot of a master node and its configuration in the Spokes admin dashboard.
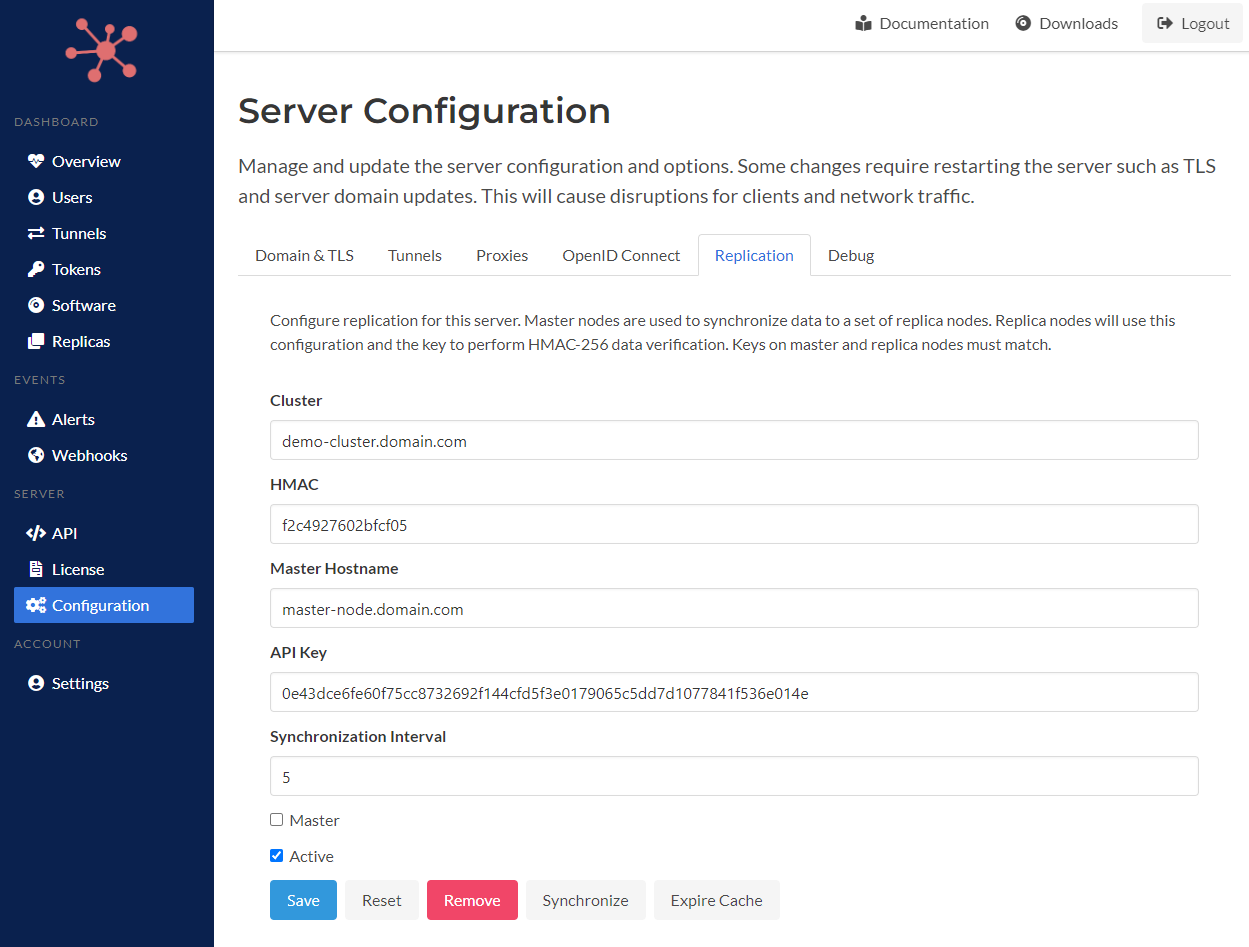
Replicaton Configuration for Server
Note: the admin API key, HMAC key, master node hostname, and cluster hostname are same across all nodes.
The HMAC key is used to create a signature for events and data published by the master node. Replica nodes use it to verify the integrity of the data they received.
In a single server Spokes instance, the hostname of Spokes server is used to create subdomains when automatic tunnel hostname assignment is turned on. For example, spokes.domain.com will create subdomains such as awesome-tun-123.spokes.domain.com. In a cluster configuration, the cluster hostname is used as the parent domain for subdomains created for new tunnels. In the future, this will allow the settings on servers to be static.
Other values such as the synchronization interval can be customized, but typically you want to keep them them identical since a snapshot is created on the master node and maintained for a period of time so that all or most replicas will receive and process the exact same snapshot.
There is an option to make the node a master. When the checkbox is checked, the node will behave as the master node in the cluster. Replica nodes have much different behavior from master and standalone Spokes servers. Replica nodes do not create or delete data. Those operations are solely performed by master nodes and replicated across the cluster. Basic updates such as the state of a tunnel, online vs. offline, can be updated by replica nodes.
Finally, the replication configuration can be made active or inactive. If you want to remove a replica node from a cluster for a moment, you can make the configuration inactive on the replica node. On the master node, you can make the matching replica entry inactive as well. We’ll discuss replica nodes and their entries on the master node in the next section.
Replication Actions
There are several buttons (actions) in the server replication form, we’ll explain them below.
Savewill commit any changes to the configuration and update the state of the server, e.g. it will make sure all changes are realized.Resetwill ignore changes and reload the replication configuration.Removewill remove the replication configuration and make changes to the state of server, such as deleting webhooks for replica nodes.Synchronizewill force a data synchronization request between a replica node and the master. If this button is clicked on a master node no actions will occur.Expire Cachewhen data synchronization operations are requested replica nodes, the master node will prepare a snapshot and cache it for three minutes. This action will expire the cache immediately.
Managing Replica Nodes
The master node maintain a list of all replica nodes in the cluster. Since it must communicate changes to the data and records stored, it needs a target to send these updates to.
The existing webhook publishing module in Spokes is used to communicate changes on the Spokes. When new replicas are created and set to active, a webhook will be generated to publish the necessary to that node to remain consistent.
The table below illustrates a single replica node that is a part of the cluster.
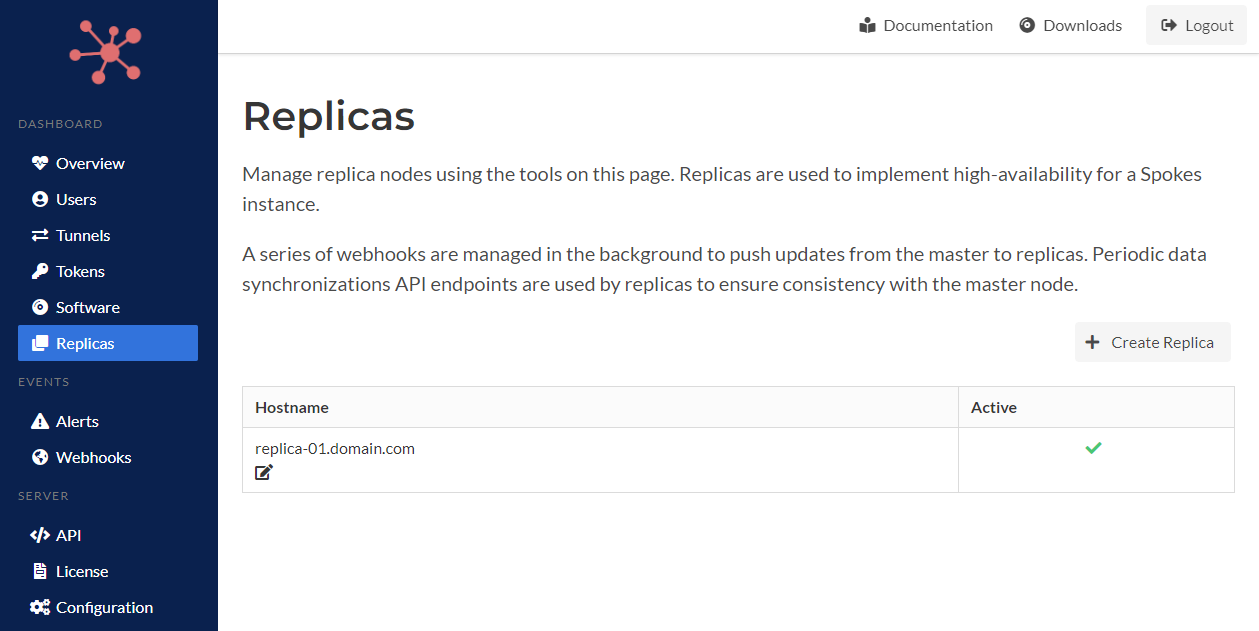
Replica List on Master Node
The master node has the ability to create replica nodes and requires a valid replication configuration that identifies the Spokes server as a master node.
A hostname is all that is needed. The hostname is used to construct a custom webhook endpoint to publish changes and new data to. It uses HTTPS by default and the path is understood internally. The active flag must be checked to replicate data to the this node. This flag can be edited on and off after it is created.
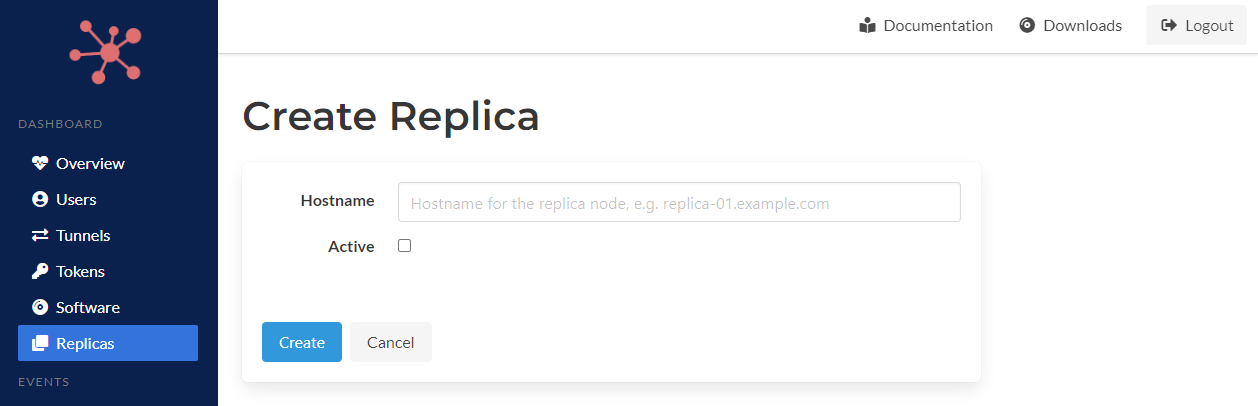
Create Replica Node
The figure below illustrates a webhook that is auto-generated to publish data and updates to a specific replica node. The configuration of this webhook cannot be changed and it is recreated each time the server replication configuration is updated and when the Spokes server starts up.
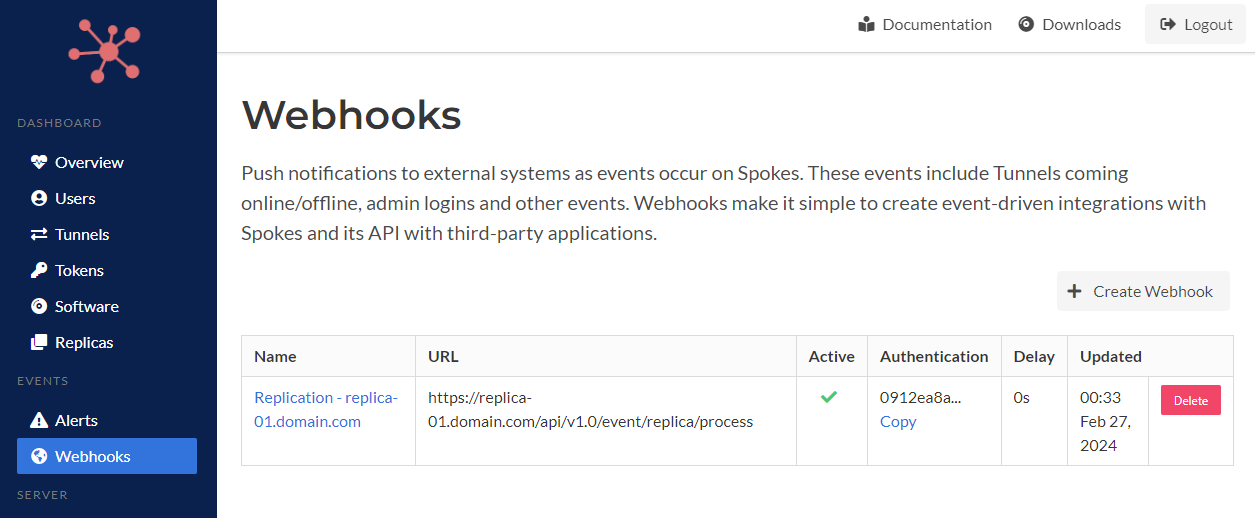
Webhook to Replicate Data to Node
Replica nodes are only managed on the master node. The underlying data is replicated to the rest of the cluster so that a replica node can be elevated to a master node as a recovery action when a failure of the master node occurs.
Replica Node Operation
In the two sections above we described how the master node is configured (via server replication settings) and updated to define a set of replica nodes. In this section we’ll discuss what replica nodes do when they receive new information from the master nodes and manage incoming client traffic.
Replica nodes all use a common endpoint path to receive and process incremental and event-based updates to critical data that is used to keep them consistent with the master node. At a high-level the data listed in the Technical Approach is created and deleted through updates published via webhooks. Some data is updated such as active/inactive states for items such as: replica nodes and registration tokens.
Maintaining Consistency
Replica nodes will also performs complete data-synchronization operations with the master node periodically. The interval for these synchronization events are configured in the Spokes server replication settings.
The idea behind full data synchronizations is that we want to ensure that replica nodes are 100% consistent. Replica nodes can be offline for a variety of reasons: crashes, software updates, or network outages.
Updates that published via webhooks but missed because the replica node is offline will eventually be introduced through these synchronization events. These synchronization events can also be used to bring new replicas online more by forcing the event in the server replication settings.
Tunnel Networking Modes
An upcoming release of our pktriot client program will support connecting to the replica nodes and set up tunneling sessions across all nodes in the cluster and request HTTP/S and TCP application traffic flows from those replicas.
This will enable the client tunnel to have an “active-active” failover posture to the cluster. Inbound Internet client traffic that is directed to a replica node because of round-robin DNS records that create an ALIAS value for the cluster hostname with the hostname of each replica node.
We also have planned another mode where the client tunnel will only create a session with the master node in the cluster. Tunnels in this mode will connect to the replica node with the highest priority when a session to the master node cannot be established. SRV records are used to identify priority for replica nodes.
These new modes are not yet available in our current pktriot release which is v0.15.2. However, in future releases we will be adding these features. Our current plan to make the active-active mode the default since it’s the most robust.
Backhaul Between Replicas and Master
Replica nodes backhaul all incoming traffic that it cannot serve to the master node.
Each replica node creates and maintains a network tunnel to the master node. These inter-node tunnels are used to relay incoming client traffic that cannot be served by the replica to the master node. Client tunnels will establish sessions with the master node in either mode they’re running in. This behavior allows the a replica node to treat the master node as a catch-all for traffic that it can’t resolve.
Failover & Recovery
In this section we’ll discuss how the approach to dealing with node failures in the cluster and how to recover when failures happen. We’ll discuss the approaches with the current version v0.15.2 of the pktriot client.
Recovery with v0.15.2 clients and earlier
The current v0.15.2 client, and earlier revisions, do not have any high-availability logic built into them. They will only attempt to reconnect to the originally configured Spokes server. Recovery requires a few manual steps to get deployed client tunnels to connect to a replica node.
Here are the steps:
- Choose one replica node from the cluster to function as the new master.
- Update DNS records for the original master server, e.g.
master.domain.comto now point to the IP addresses (v4 and/or v6) to the chosen replica node. - Login into the replica node and visit the Settings -> Replication tab.
- Change the node setting from Replica to Master. This requires just clicking the
Mastercheckbox.
- Change the node setting from Replica to Master. This requires just clicking the
- Login into the replica node and visit the Settings-> Domain & TLS tab.
- Change the domain name to the failed master node’s hostname. Note, we updated the DNS record for this hostname in the steps earlier.
- Update any custom certificates. If you’re using Lets Encrypt or another External ACME provider, new TLS certificates will be created automatically.
- Update the DNS records for the cluster hostname to drop the original master node to prevent Internet client from resolving addresses for the failed node.
The replica node will restart and now realize the new hostname. Client tunnels will pick up the change via DNS and being connecting to the new master node.
Once the original master node is restored, it can be reintegrated as a replica node. If you intend to reinstate the original master node as the actual master node, you will need to set it up as a replica, force a synchronization with the current master node to get the latest data, and then you can change DNS and server settings to reinstate the master node.
Note, this isn’t a necessary step unless there is a good reason to do it. For example, perhaps the original master node was configured with more compute and memory resources then the replicas.
Recovery with Future Clients
In our future client releases we are planning to automate as much of failover and recovery actions necessary. Our approach will include using SRV DNS records to fetch a list of nodes for the cluster and identify the master and replicas. SRV records enable us to define a service and then several prioritized hostnames that can be used to access this service.
Our future client releases will also make use of the cluster hostname. For example, tunnels connecting to a cluster will use the cluster hostname when identifying the Spokes instance. The client will check if an SRV record exists, if so, then it’ll realize it’s connecting to a cluster and will then pick out the master node and run the configuration operation on that node.
Future tunnel sessions will perform the SRV lookup each time so it can understand the current state and connect to the right servers.
Conclusion on HA
The new cross-region high-availability features will require an updated client for the active-active and failover functionality. However, current and older clients will operate as they presently do in these new HA clusters without any disruption.
The new HA functionality built into Spokes can be used to prevent a catastrophic loss. At the moment, recovery requires some manual steps so that tunnels can reestablish sessions with a new master node, but the goal is to automate as much of that as possible in the future.
Roadmap
Our docs will receive an update to cover many of the topics we shared in this blog post.
In the next few weeks, and months, we will be focusing on adding updates to our client to automate recovery and be more aware of the cluster. We expect there will be rough edges in our cross-region HA implementation that we will need to smooth out.
Our goal is to build a fully automated, cross-region, high-available network server, where the cluster and tunnels can auto-detect failures and adjust with little to no intervention from administrators. To make this possible we will need a new application to manage the state of DNS records and monitor the nodes in the cluster. Right now we’re referring to this new application as the sentinel.
We would like to make server configuration for each node in the cluster a little more simple by potentially eliminating the master flag. Ideally, the identification of master node could be done with SRV records that are maintained by the sentinel service.
Thanks!
Thanks to our customers who’ve been licensing Spokes over the years. Some of their needs have grown to requiring advanced features like cross-region high-availability. It’s an exciting new capability to add to Spokes and solves a problem that is very difficult to solve.
If you have any issues deploying our new cross-region HA, please be sure to reach out to us as we’d like to learn how to we can improve our documentation and simplify implementing high-availability with Spokes.
We also appreciate the bug reports and feature requests our users send us! Let us know if we can focus on any new features or improvements we can add to Spokes.
Cheers!